JAVA-JVM内存模型
基本内容
指令重排(编译器、运行时)
从java源代码到最终实际执行的指令序列,会分别经历下面三种重排序:
编译器优化重排序
指令级并行重排序
内存系统重排序
编译器优化重排序
在执行程序时,为了提高性能,编译器和处理器会对指令做重排序。但是,JMM确保在不同的编译器和不同的处理器平台之上,通过插入特定类型的Memory Barrier来禁止特定类型的编译器重排序和处理器重排序,为上层提供一致的内存可见性保证。
指令级并行重排序
编译器优化重排序:编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
指令级并行的重排序:现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
内存系统重排序
内存系统的重排序:处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行(强调的是内存缓存)。
在虚拟机层面,为了尽可能减少内存操作速度远慢于CPU运行速度所带来的CPU空置的影响,虚拟机会按照自己的一些规则将程序编写顺序打乱——即写在后面的代码在时间顺序上可能会先执行,而写在前面的代码会后执行——以尽可能充分地利用CPU
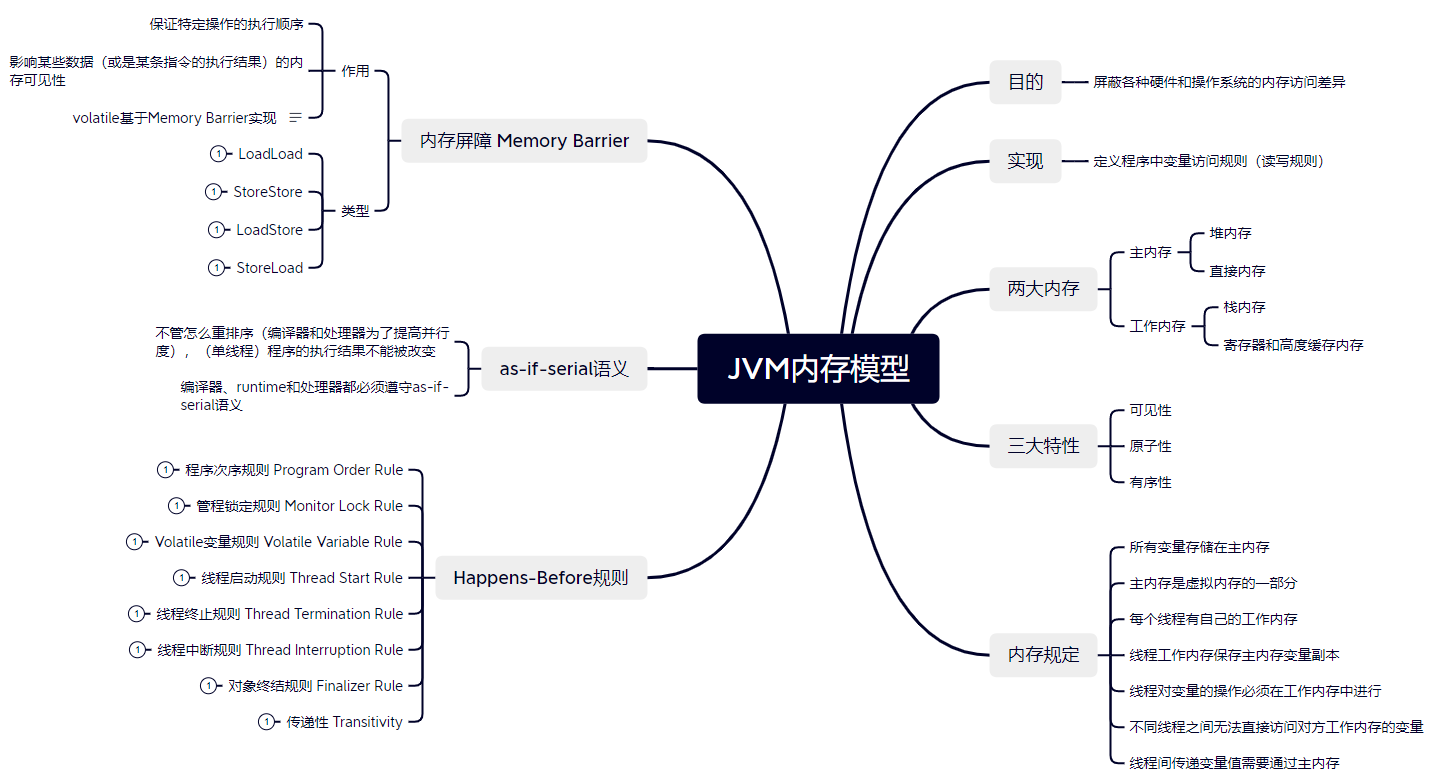
内存屏障
内存屏障类型
- LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
- StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
- LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
基于保守策略的JMM内存屏障插入策略:
- 在每个volatile写操作的前面插入一个StoreStore屏障
- 在每个volatile写操作的后面插入一个StoreLoad屏障
- 在每个volatile读操作的后面插入一个LoadLoad屏障
- 在每个volatile读操作的后面插入一个LoadStore屏障